
AI Fundamentals: RAG
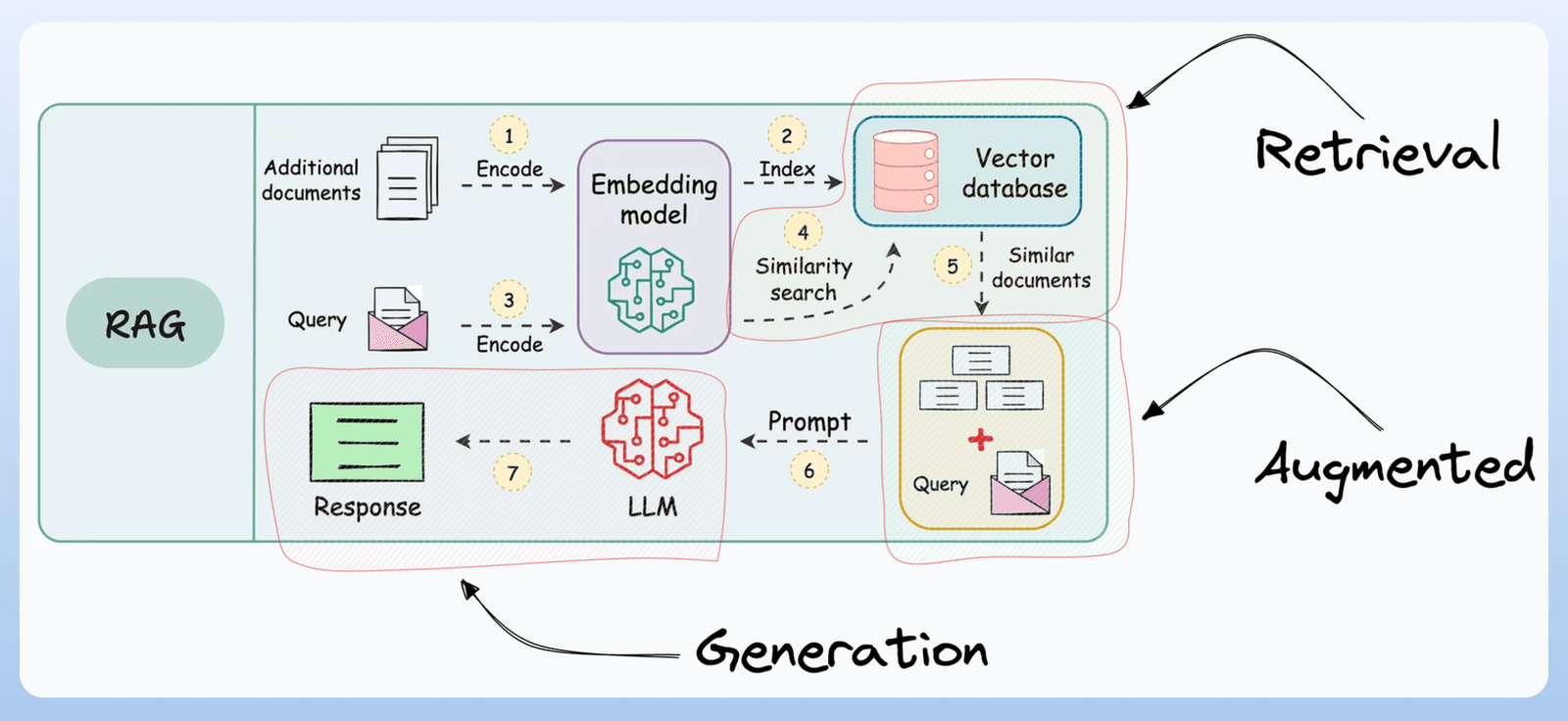
Lets try to understand why RAG is needed. Gen AI exists due to modern day LLMs and why we need RAG when there are LLM's.
Part 1️⃣: Limitations of LLMs
🔍 1. LLMs are powerful but flawed
| Limitation | Details | Impact |
|---|---|---|
| ❌ Knowledge Cutoff | Models are trained on past data | Cannot answer recent news, latest updates, real-time information |
| ❌ No Access to Private Data | Cannot access company documents, internal databases, personal files | Cannot build enterprise tools using raw LLMs alone |
| ❌ Hallucination | Model generates confident but wrong answers | No guarantee of factual correctness |
Part 2️⃣: Fine-Tuning Deep Dive
Fine-tuning = Training the model again on your custom dataset so it learns that data internally
❌ Problems with Fine-Tuning
| Problem | Details | Impact |
|---|---|---|
| Expensive | Requires: GPUs, Training pipeline | Not cheap for most use cases |
| Time-Consuming | Training takes time | Not instant or iterative |
| Not Scalable for Updates | Your data changes frequently → you must retrain again and again | Becomes impractical very quickly |
| Static Knowledge | Once trained, model knowledge is fixed | Cannot dynamically fetch new info |
Fine-Tuning Workflow — Notes
💡 Quick Reminder
Remember: The 4-step workflow below applies to any fine-tuning approach. The key difference is in Step 2 (which method you choose) — everything else is the same!
🌳 Fine-Tuning Workflow (4-Step Process)
Fine-Tuning Workflow
├── 🟢 1. Data Collection
│ ├── High-quality prompt → response pairs
│ ├── Dataset size: Few hundred → few hundred thousand
│ ├── Quality > Quantity
│ └── Must be: Clean, Relevant, Consistent
│
├── 🟢 2. Choose Fine-Tuning Method
│ ├── Full Fine-Tuning (Full FT)
│ │ ├── Updates: All model parameters
│ │ ├── Cost: High
│ │ └── Performance: Best
│ ├── LoRA / QLoRA ⭐ Most Common
│ │ ├── Updates: Small subset of parameters
│ │ ├── Cost: Low
│ │ └── Performance: Very good
│ └── Adapters
│ ├── Updates: Adds small modules to model
│ ├── Cost: Low
│ └── Performance: Moderate
│
├── 🟢 3. Training
│ ├── Train for few epochs (few passes over data)
│ ├── Full FT → Update entire model
│ ├── LoRA → Keep base model frozen, update small layers
│ └── Risk: Overfitting → model becomes too rigid
│
└── 🟢 4. Evaluation & Safety Testing
├── Metrics
│ ├── Exact Match: Does output match expected answer?
│ ├── Factuality: Is the answer correct?
│ └── Hallucination Rate: Does model generate false info?
└── Safety Testing (Red Teaming)
├── Edge cases
├── Malicious inputs
└── Unsafe prompts
🟢 Choose Fine-Tuning Method
Comparison Table:
| Method | Updates | Cost | Performance | Use Case |
|---|---|---|---|---|
| Full Fine-Tuning (Full FT) | All model parameters | High | Best | Large-scale systems |
| LoRA / QLoRA | Small subset of parameters | Low | Very good | Most real-world apps |
| Adapters | Adds small modules to model | Low | Moderate | Lightweight setups |
💡 Fine-Tuning: Key Takeaways
🎯 REMEMBER: Fine-tuning modifies the model itself (weights) — this is permanent and expensive
| Aspect | Details |
|---|---|
| What changes | Fine-tuning modifies the model itself (weights) |
| Requirements | Data, Compute, Evaluation pipeline |
| Expensive | Yes |
| Time-consuming | Yes |
| Update frequency | Hard to update frequently |
| Best for | Not suitable for dynamic data |
⚠️ Fine-Tuning Inefficiency Deep Dive
Fine-tuning becomes inefficient and costly, and LLM limitations can't be solved efficiently.
📌 Practical Scenario: Why Fine-Tuning Fails in Real World
| Timeline | Action | Result | Problem | Lesson |
|---|---|---|---|---|
| Month 1 | Fine-tune on 500 HR policy examples | Works well ✓ | None | Model trained successfully |
| Month 2 | Company updates parental leave policy | Must retrain entire model (2-3 days) | Expensive, time-consuming | Data changed → costs explode |
| Month 3 | New remote work policy added | Retrain again | Endless retraining cycle | Not scalable for dynamic data |
| Month 4 | Model knowledge 3 months behind | Hallucinating outdated info | Worse than baseline | Static knowledge becomes liability |
Root Problem: You're trying to update model weights (static, expensive)
Better Approach (RAG): Update external documents (dynamic, instant) — No retraining needed, model always has latest info
In-Context Learning (ICL)
Definition: A core capability of LLMs where the model learns to solve a task purely by seeing examples in the prompt — without updating weights.
Key Property: Zero training needed. Examples in prompt = instant learning.
📌 Practical Example: Sentiment Analysis
The sources describe a primary example involving Sentiment Analysis using a technique called "Few-Shot Prompting".
In this scenario, a user provides the LLM with a few labeled examples directly within the prompt to teach it a pattern:
- Example 1: "I love this phone" → Sentiment: Positive
- Example 2: "This app crashes a lot" → Sentiment: Negative
- Example 3: "The camera is amazing" → Sentiment: Positive
- The Query: "I hate the battery life"
The LLM observes these previous examples, learns how to perform sentiment analysis for this specific context, and correctly identifies the sentiment of the final text as Negative without ever having been explicitly retrained on this data.
Part 3️⃣: Emergent Properties & Behaviors
Emergent Properties
Definition: A behavior or ability that suddenly appears in a system when it reaches a certain scale or complexity - even though it was not explicitly programmed.
Origin: Started appearing in GPT-3 (175B parameters) — became more pronounced in larger models.
In-context learning = Emergent property ✓
Emergence Mechanics
| What Emerges | Why It's Emergent | When It Appears |
|---|---|---|
| Model learns task from examples in prompt | Not explicitly trained for this | At scale (100B+ params) |
| No weight updates, no training needed | Capability wasn't hard-coded | Naturally as complexity increases |
| Reasoning ability | Not trained on reasoning tasks | Emerges with size |
| Instruction-following | Not explicitly trained for all instructions | Emerges from scale |
Key Insight for PMs
You cannot predict or control what emerges. This is why:
- ✅ You get useful reasoning
- ❌ You also get hallucinations
- Both are features of the same underlying phenomenon
🔴 Negative Emergent Behaviors (VERY IMPORTANT)
| Behavior | Definition | Real-World Impact | Detection Method |
|---|---|---|---|
| ❌ Hallucination | Generates false but confident answers | Customer gets wrong info, loss of trust | Manual review, fact-checking |
| ❌ Overconfidence | Sounds certain even when wrong | User trusts bad answer | Confidence score analysis |
| ❌ Prompt Sensitivity | Small prompt change → very different output | Inconsistent behavior, unpredictable | A/B testing different phrasings |
| ❌ Bias Amplification | Learns and amplifies training data biases | Discriminatory outputs, regulatory risk | Bias audits, demographic testing |
🧠 What ties all these together
👉 These abilities:
- Were not explicitly programmed
- Appear when:
- Model size increases
- Data increases
- Training improves
Emergent Properties & Trade-offs
The Core Tension
Positive emergent behaviors (reasoning, instruction-following) and negative ones (hallucination, overconfidence) both emerge together as scale increases. You cannot suppress one without potentially losing the other.
Why This Matters
Solution: Don't try to "fix" the model. Instead:
- Leverage positive emergent behaviors (reasoning)
- Contain negative ones (guardrails, RAG)
📌 Interview Case Study: Fintech Customer Support Chatbot
Question: You are building a customer support chatbot for a fintech app.
During testing, you notice:
- The model can follow complex instructions without training
- It sometimes reasons step-by-step correctly
- But it also hallucinates occasionally
Explain why this is happening and how you would design the system to handle it.
Step 1: Identify Emergent Behavior
The model is showing emergent properties. Capabilities like instruction-following and step-by-step reasoning were not explicitly programmed but arise as the model scales.
Step 2: Explain BOTH sides (this is key)
Along with useful abilities, negative behaviors like hallucinations also emerge. These are not bugs but inherent to how LLMs work.
Step 3: Explain WHY this happens
The model generates responses based on patterns in data rather than verified knowledge, which leads to variability—sometimes correct reasoning, sometimes incorrect but confident outputs.
Step 4: Design Implication (this is where most fail)
Because of this, we cannot rely solely on the model. The system should include:
- Retrieval (RAG) to ground responses in real data
- Guardrails to filter unsafe or incorrect outputs
- Evaluation mechanisms to monitor hallucination rates
Part 4️⃣: Knowledge Storage & Pre-training Limitations
Knowledge Storage Models in LLMs
Two Types of Knowledge
| Type | Storage | Update Speed | Reliability | Use Case |
|---|---|---|---|---|
| Parametric Knowledge | Inside model weights | Requires retraining (days) | Medium (hallucinations) | General knowledge |
| External Knowledge (RAG) | Outside model (vector DB) | Instant (update docs) | High (verified sources) | Grounded facts |
Mental Model
Parametric Knowledge = Model's long-term memory (learned during training)
RAG / External = Model's short-term reference (looked up at query time)
Best practice: Use both:
- Parametric → Reasoning, common sense
- External → Facts, company-specific info
Why Pre-training is NOT the Solution
| Reason | Core Problem | Cost/Time Impact | Example | Better Alternative |
|---|---|---|---|---|
| 🟢 Cost of Training | Requires huge compute (GPUs/TPUs) + months | 100K-1M+ per run, 1-3 months | Training 7B model costs 50K-100K | Use RAG instead |
| 🟢 Data Changes Constantly | Real-world data updates frequently → must retrain | Every policy change = full retrain cycle | Month 1: train on Q1 data, Month 2: retrain for policy change | Retrieve from updated docs instantly |
| 🟢 Knowledge Gets Locked | Once trained, knowledge frozen in weights | Months to add new domain, fix errors | To correct hallucination: Full retrain required | Update source documents in minutes |
| 🟢 Not Scalable | Each new domain/use case = separate model | 3 domains = 3 models, 3x maintenance overhead | HR model + Finance model + Legal model | 1 base model + 3 RAG indexes |
Part 5️⃣: RAG (Retrieval-Augmented Generation)
✅ What RAG Does Instead (The Smart Solution)
Core Philosophy
Instead of: Storing knowledge IN the model (expensive, static)
Do this: Keep knowledge OUTSIDE, retrieve as needed (cheap, dynamic)
RAG Architecture Comparison
| Aspect | Pre-training | RAG |
|---|---|---|
| Knowledge location | Inside model weights | External vector database |
| Update speed | Days to weeks (retrain) | Minutes (upload doc) |
| Cost to update | 50K-500K+ | $0 |
| Scalability | One model per domain | One model, many data sources |
| Maintenance | Model management | Data management |
| Hallucination risk | High (facts unreliable) | Low (grounded in sources) |
RAG is preferred because: It allows using external and frequently changing data without retraining the model, making the system more efficient and scalable.
RAG: Formal Definition
RAG (Retrieval-Augmented Generation) = Technique where a system:
- Retrieves relevant external information
- Augments (adds) that info to the prompt
- Generates accurate responses using both
One-liner: "Let the LLM read from external documents before answering."
🎯 RAG Scenario: Leave Policy Question
User Question: "What is my company's leave policy?"
| Phase | WITHOUT RAG (Model Alone) | WITH RAG (Grounded Answer) | Outcome |
|---|---|---|---|
| Source | Parametric knowledge only | Searches HR_Policy_2024.pdf | Factual document found |
| Retrieval | ❌ No external docs searched | ✅ Retrieves: "20 paid leaves + 2 sick + 5 personal" | Company-specific data available |
| Answer Quality | Generic ("15-20 days typical") or Hallucinated ("30 days!") | Specific ("20 paid leaves + 2 sick + 5 personal") | Accurate, verifiable |
| Trustworthiness | Low - user doubts accuracy | High - cited source (HR Policy 2024) | User confident in answer |
| Update Handling | Must retrain model ($50K+) | Update doc instantly ($0) | Dynamic, low-maintenance |
Step-by-Step Breakdown:
- Retrieve → Searches company documents → Finds relevant section → "Employees entitled to 20 paid leaves..."
- Augment → Adds to prompt → Context + Question combined
- Generate → Model produces grounded answer → "Your company provides 20 paid leaves per year"
Mapping to RAG: Retrieval ✓ | Augmented ✓ | Generation ✓
When to Choose: Fine-Tuning vs RAG
Fine-Tuning when the model needs to learn new behavior or style (static use case).
RAG when data changes frequently or you need access to real-time/private information (dynamic use case).
RAG Breakdown & Core Idea
| Component | Definition |
|---|---|
| Retrieval | Fetch relevant data |
| Augmented | Add that data to prompt |
| Generation | LLM generates answer |
Simple Analogy
| Scenario | Approach |
|---|---|
| Without RAG | Student answering from memory |
| With RAG | Student allowed to open book before answering |
💡 KEY INSIGHT: RAG Solves 3 LLM Limitations
- Knowledge Cutoff → Fetch latest data in real-time
- No Private Data → Retrieve company-specific information
- Hallucination → Ground responses in actual retrieved facts
Complete RAG Definition
RAG is a system where instead of relying only on pretrained knowledge, we retrieve relevant external data using embeddings and vector search, then augment the prompt with that data before passing it to the LLM for grounded response generation.
End-to-End RAG Flow
| Step | Action |
|---|---|
| 1 | User asks question |
| 2 | Retriever finds relevant chunks |
| 3 | Combine: Query + Retrieved data |
| 4 | Pass to LLM |
| 5 | LLM generates answer |
RAG System: 4-Step Architecture
A complete RAG system consists of 4 sequential phases:
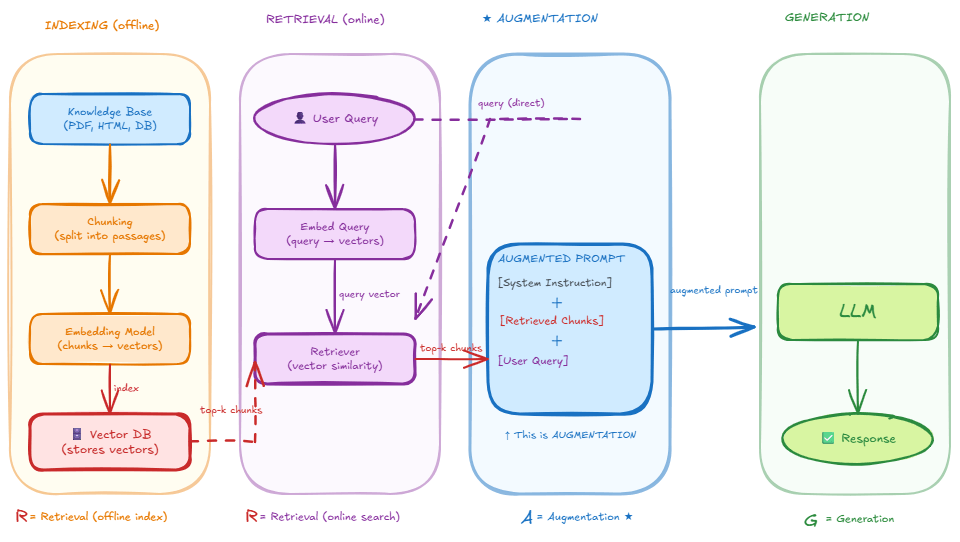
Key insight: Phase 1 runs once offline. Phases 2-4 run for every query.
🌳 Phase 1: Indexing Pipeline (Offline Setup)
| Step | What | Why | Tools | Data Flow |
|---|---|---|---|---|
| 1. Data Ingestion | Load source knowledge into memory | Start with raw data | LangChain loaders (PyPDFLoader, YoutubeLoader, WebBaseLoader, GitLoader) | WWW → Document Loader → Documents |
| 2. Chunking | Break large docs into small, meaningful chunks | LLM token limits + better retrieval precision | RecursiveCharacterTextSplitter, MarkdownHeaderTextSplitter, SemanticChunker | Docs → Text Splitter → Multiple chunks |
| 3. Embeddings | Convert each chunk to dense vector capturing meaning | Enable semantic similarity search ("car" ≈ "vehicle") | OpenAIEmbeddings, SentenceTransformerEmbeddings, InstructorEmbeddings | Chunks → Embedding Model → Dense Vectors |
| 4. Vector Database | Store vectors + chunk text + metadata | Fast similarity search at query time | FAISS (local), Pinecone (cloud) | Vectors → Vector Store → External Knowledge |
⚠️ Important: Entire pipeline runs BEFORE user queries (Indexing Phase / Offline Phase)
💡 Mental Model: The Google Search Analogy
Indexing Phase ≈ Building Google's search index
- Run once (slow, thorough): Takes hours/days
- Then reuse forever: Queries return in milliseconds
That's why RAG is so fast in production!
Google's approach:
Year 1: Crawl and index entire web (massive effort)
Year 2+: User queries return in milliseconds
RAG's approach:
Week 1: Index company docs (one-time effort)
Week 2+: User queries return in milliseconds
🌳 Phase 2: Retrieval (Real-Time Query Processing)
Definition: Real-time process of finding the most relevant pieces of information from the pre-built index.
| Retrieval Step | What Happens | Input | Output |
|---|---|---|---|
| 1. Query to Embedding | Convert user query to vector using same embedding model | User question: "What is my leave policy?" | Query embedding vector |
| 2. Vector Search | Search vector DB for similar embeddings (cosine similarity) | Query vector + all stored vectors | Top-K matching chunks (usually 3-5) |
| 3. Return Matches | Get original chunk text + metadata from matches | Similar embeddings found | Relevant text passages |
| 4. Pass to LLM | Send matched chunks to Phase 3 (Augmentation) | Selected chunks | Ready for augmentation |
Core Question: "From all indexed documents, which 3–5 chunks best match this query?"
🌳 Phase 3: Augmentation (Prompt Engineering)
Definition: Combining retrieved documents with the user's query to create an enriched prompt.
| Element | Role | Example |
|---|---|---|
| Retrieved Context | Ground truth data | "Employees are entitled to 20 paid leaves per year, 2 sick leaves, and 5 personal days" |
| User Question | What we need answered | "What is my company's leave policy?" |
| Template Format | Structure to combine them | Context: [chunks] → Question: [query] → Answer (use only context) |
| Output | Ready-to-send prompt | Full prompt sent to LLM in Phase 4 |
Why This Matters:
- ✅ LLM sees relevant facts first
- ✅ Reduces hallucinations (facts in context)
- ✅ Answers are traceable (sources known)
🌳 Phase 4: Generation (LLM Response)
Definition: Final step where LLM uses augmented prompt to generate a response.
| Generation Element | What Happens | Result |
|---|---|---|
| Input | Augmented prompt (context + query) | LLM sees facts before generating |
| Processing | LLM reads context, understands query, generates answer | Grounded reasoning using provided facts |
| Output Format | Answer + source citations | Traceable, verifiable response |
| Key Advantage | Facts in context prevent hallucinations | ✅ Grounded ✅ Reduced hallucination ✅ Citable |
Typical Output:
Answer: Your company provides 20 paid leaves per year,
2 sick leaves, and 5 personal days.
Sources:
- HR Policy 2024, Section 3.1
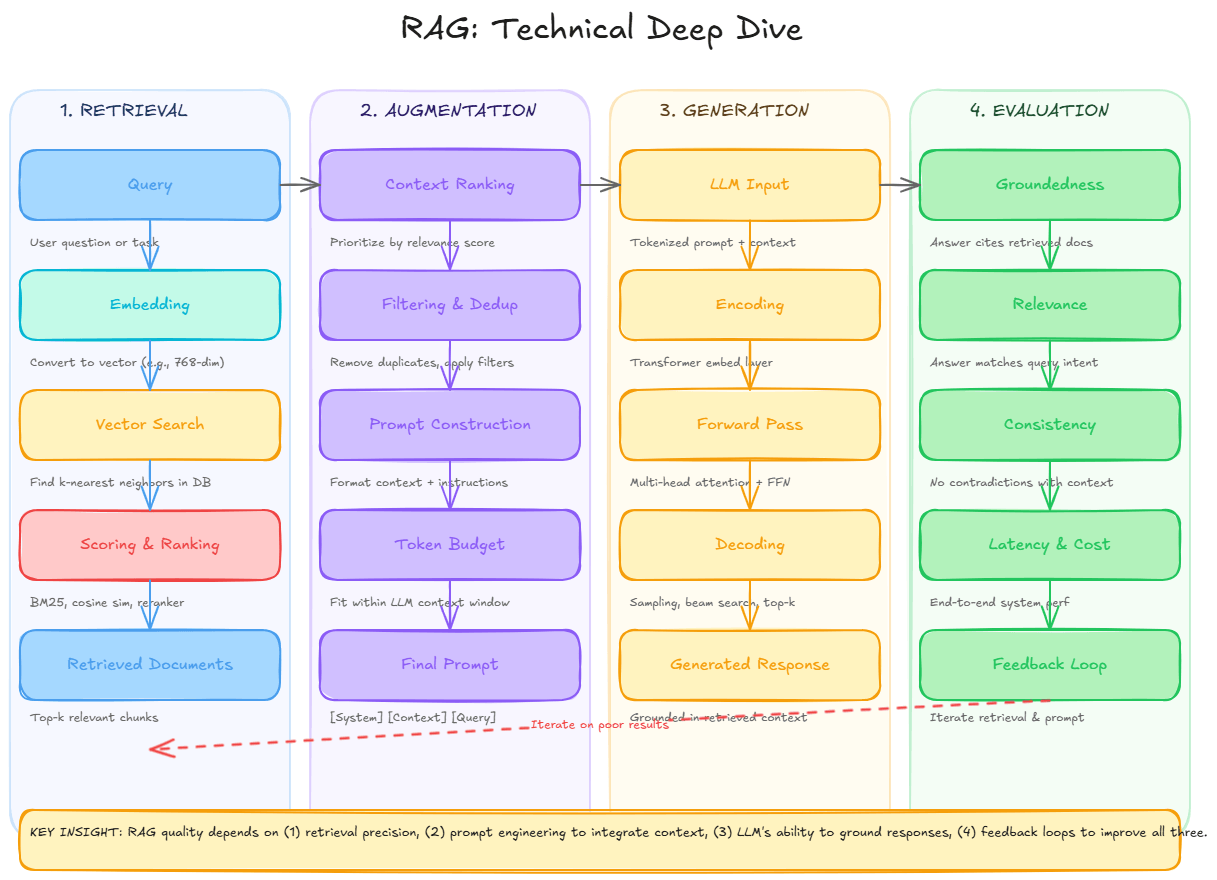
RAG System End-to-End Flow
This comprehensive guide covers everything you need to understand RAG and why it's the preferred approach for building grounded AI systems that work with real-world data.